Four-Layer Silent Proxy Architecture
Each layer is independently scalable and auditable. The entire pipeline completes in under 50ms for most document types.
Silent Proxy Layer
Network Edge Interception
Deployed as a transparent network proxy, OPSEC Scrub intercepts all outbound file transfers at the perimeter. No endpoint agents required. No user-facing prompts. Supports HTTP, HTTPS, SMTP, FTP, and cloud storage APIs.
AI Classification Engine
Document Intelligence
A fine-tuned transformer model classifies each file by type and sensitivity level before sanitization begins. Supports 200+ file formats including PDF, DOCX, XLSX, PPTX, JPEG, PNG, MP4, and ZIP archives.
Sanitization Engine
47+ Field Removal
The core sanitization pipeline strips 47+ metadata categories using format-specific parsers. Each parser is maintained against the latest format specifications to ensure complete coverage as standards evolve.
Audit Log System
Immutable Evidence Trail
Every sanitization event generates a cryptographically signed log entry stored in an append-only database. Logs include: file hash (before/after), fields removed, timestamp, user context, and destination.
Machine learning that reads what humans miss.
Standard metadata strippers miss embedded PII in document body text, image captions, and custom XML properties. Our NER (Named Entity Recognition) model identifies and redacts personal data that rule-based systems cannot detect.
The model is trained on UK-specific data patterns including NHS numbers, NI numbers, UK postcodes, and Companies House identifiers.
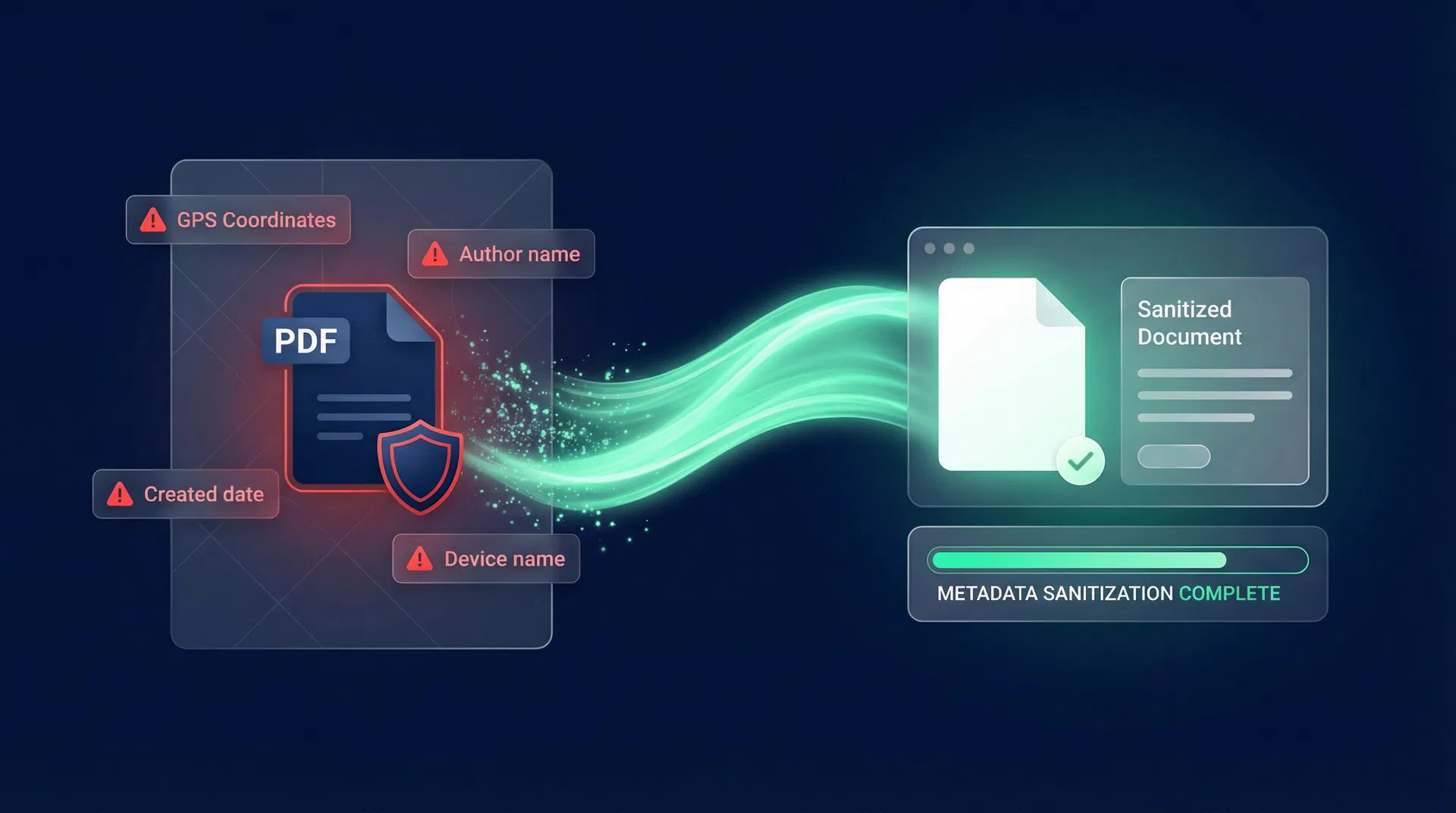
47+ Metadata Fields Stripped
Every field that could identify your people, your infrastructure, or your processes.
200+ File Formats Supported
Documents
Images
Archives
Media
Code/Data
Ready to see it in action?
Upload a sample file and receive a free Metadata Risk Audit. No account required.